电话:020-66888888

DeepSeek现已宣布FlashMLA,AI推理速率再晋升!
作者:[db:作者] 发布时间:2025-03-05 09:06
在AI技巧飞速开展的明天,年夜模子已成为推进人工智能利用落地的中心引擎。但是,跟着模子范围的一直扩展,推理效力低、资本耗费高级成绩也逐步凸显。 为懂得决这一行业痛点,2025年2月24日,深度求索(DeepSeek)在首届“开源周”运动上,正式宣布了首个开源代码库——FlashMLA
为懂得决这一行业痛点,2025年2月24日,深度求索(DeepSeek)在首届“开源周”运动上,正式宣布了首个开源代码库——FlashMLA 什么是FlashMLA?FlashMLA是一个能让年夜言语模子在H800如许的GPU上跑得更快、更高效的优化计划,尤其实用于高机能AI义务。这一代码可能减速年夜言语模子的解码进程,从而进步模子的呼应速率跟吞吐量,这对及时天生义务(如谈天呆板人、文本天生等)尤为主要。
什么是FlashMLA?FlashMLA是一个能让年夜言语模子在H800如许的GPU上跑得更快、更高效的优化计划,尤其实用于高机能AI义务。这一代码可能减速年夜言语模子的解码进程,从而进步模子的呼应速率跟吞吐量,这对及时天生义务(如谈天呆板人、文本天生等)尤为主要。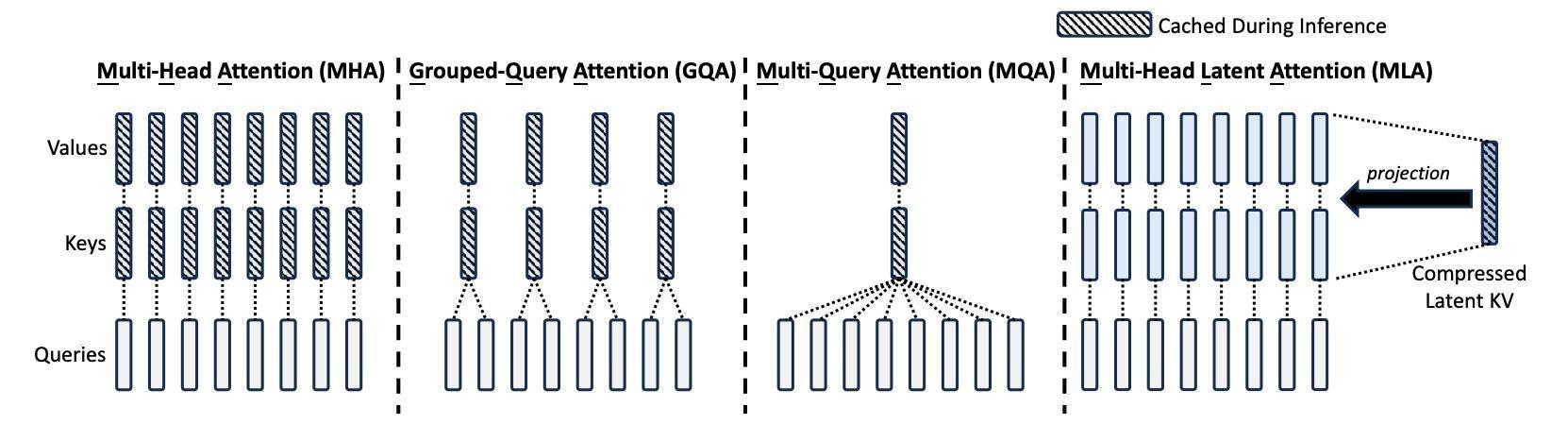 FlashMLA的用途1.算力挪用晋升,降本增效详细来说,FlashMLA能够冲破GPU算力瓶颈,下降本钱。传统解码方式在处置差别长度的序列(如翻译差别长度的输入文本)时,GPU的并行盘算才能会被挥霍,就像用卡车运小包裹,年夜局部空间闲置。而FlashMLA的改良是:经由过程静态调理跟内存优化,将HopperGPU(如H100)的算力“榨干”,雷同硬件下吞吐量明显晋升。这象征着用户能够挪用更少的GPU来实现同样的义务,年夜幅下降了推理365速发国际官网本钱。
FlashMLA的用途1.算力挪用晋升,降本增效详细来说,FlashMLA能够冲破GPU算力瓶颈,下降本钱。传统解码方式在处置差别长度的序列(如翻译差别长度的输入文本)时,GPU的并行盘算才能会被挥霍,就像用卡车运小包裹,年夜局部空间闲置。而FlashMLA的改良是:经由过程静态调理跟内存优化,将HopperGPU(如H100)的算力“榨干”,雷同硬件下吞吐量明显晋升。这象征着用户能够挪用更少的GPU来实现同样的义务,年夜幅下降了推理365速发国际官网本钱。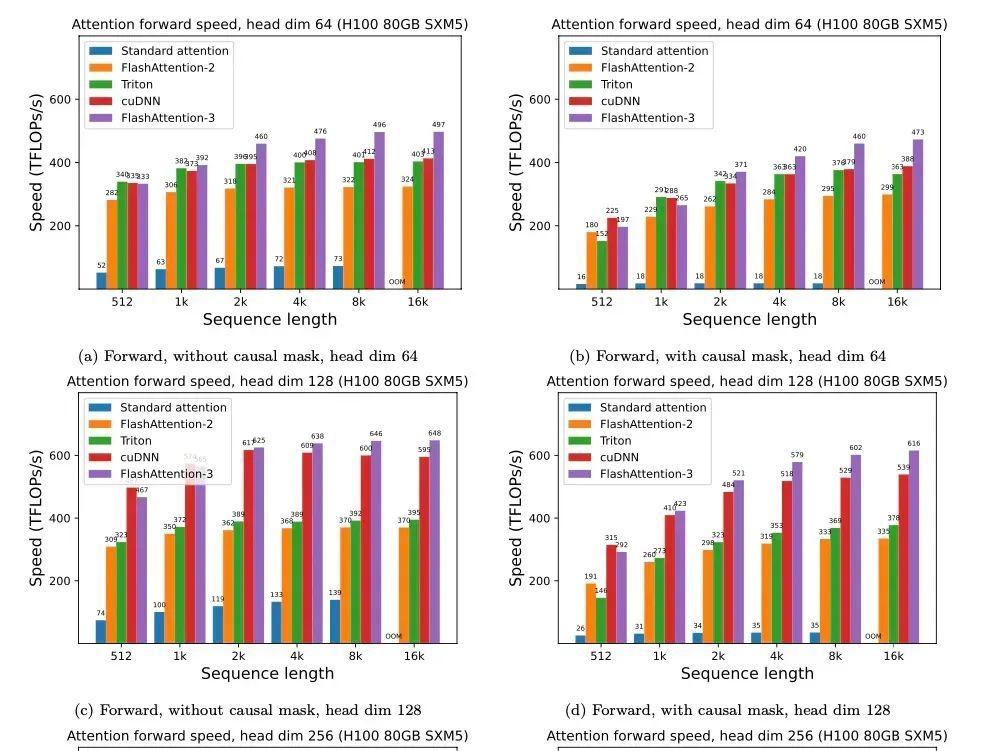 2. 推理速率晋升经DeepSeek 实测,FlashMLA在 H800SXM5 平台上(CUDA12.6),在内存受限设置下可达最高 3000GB/s,在盘算受限设置下可达峰值 580TFLOPS,堪称是速率晋升宏大。FlashMLA 的应用场景及时天生义务:如谈天呆板人、文本天生、及时翻译等须要低耽欧洲杯app误、高吞吐量的场景。年夜模子推理减速:实用于GPT、BERT等年夜范围言语模子的推理义务。节俭推理本钱:经由过程增加GPU 应用量,明显下降推理本钱,合适中小企业或硬件资本无限的情况。
2. 推理速率晋升经DeepSeek 实测,FlashMLA在 H800SXM5 平台上(CUDA12.6),在内存受限设置下可达最高 3000GB/s,在盘算受限设置下可达峰值 580TFLOPS,堪称是速率晋升宏大。FlashMLA 的应用场景及时天生义务:如谈天呆板人、文本天生、及时翻译等须要低耽欧洲杯app误、高吞吐量的场景。年夜模子推理减速:实用于GPT、BERT等年夜范围言语模子的推理义务。节俭推理本钱:经由过程增加GPU 应用量,明显下降推理本钱,合适中小企业或硬件资本无限的情况。 现在该名目已支撑在GITHUB高低载,想要休会的同窗能够经由过程下365国际速发平台官网方地点自行搭载哦~https://github.com/deepseek-ai/FlashMLA,参数如下图所示;
现在该名目已支撑在GITHUB高低载,想要休会的同窗能够经由过程下365国际速发平台官网方地点自行搭载哦~https://github.com/deepseek-ai/FlashMLA,参数如下图所示; 固然,手握花费级显卡的小搭档也不要悲观~公道应用PC硬件,当地安排一套DeepSeek-R1(INT-4)模子用来办公、进修也是不错的抉择!固然,最好是应用影驰最新推出的GeForceRTX 50系列显卡来停止当地安排!
固然,手握花费级显卡的小搭档也不要悲观~公道应用PC硬件,当地安排一套DeepSeek-R1(INT-4)模子用来办公、进修也是不错的抉择!固然,最好是应用影驰最新推出的GeForceRTX 50系列显卡来停止当地安排! 影驰GeForceRTX 50系列显卡采取NVIDIA全新Blackwell架构,搭载第二代Transformer引擎,支撑4位浮点(FP4) AI,从而减速年夜言语模子(LLM) 跟专家混杂模子(MoE)的推理跟练习!抉择它们作为你的出产力显卡,能够说是再适合不外!欢送列位小搭档们前去影驰官方商城选购哦~
影驰GeForceRTX 50系列显卡采取NVIDIA全新Blackwell架构,搭载第二代Transformer引擎,支撑4位浮点(FP4) AI,从而减速年夜言语模子(LLM) 跟专家混杂模子(MoE)的推理跟练习!抉择它们作为你的出产力显卡,能够说是再适合不外!欢送列位小搭档们前去影驰官方商城选购哦~
为懂得决这一行业痛点,2025年2月24日,深度求索(DeepSeek)在首届“开源周”运动上,正式宣布了首个开源代码库——FlashMLA什么是FlashMLA?FlashMLA是一个能让年夜言语模子在H800如许的GPU上跑得更快、更高效的优化计划,尤其实用于高机能AI义务。这一代码可能减速年夜言语模子的解码进程,从而进步模子的呼应速率跟吞吐量,这对及时天生义务(如谈天呆板人、文本天生等)尤为主要。FlashMLA的用途1.算力挪用晋升,降本增效详细来说,FlashMLA能够冲破GPU算力瓶颈,下降本钱。传统解码方式在处置差别长度的序列(如翻译差别长度的输入文本)时,GPU的并行盘算才能会被挥霍,就像用卡车运小包裹,年夜局部空间闲置。而FlashMLA的改良是:经由过程静态调理跟内存优化,将HopperGPU(如H100)的算力“榨干”,雷同硬件下吞吐量明显晋升。这象征着用户能够挪用更少的GPU来实现同样的义务,年夜幅下降了推理365速发国际官网本钱。2. 推理速率晋升经DeepSeek 实测,FlashMLA在 H800SXM5 平台上(CUDA12.6),在内存受限设置下可达最高 3000GB/s,在盘算受限设置下可达峰值 580TFLOPS,堪称是速率晋升宏大。FlashMLA 的应用场景及时天生义务:如谈天呆板人、文本天生、及时翻译等须要低耽欧洲杯app误、高吞吐量的场景。年夜模子推理减速:实用于GPT、BERT等年夜范围言语模子的推理义务。节俭推理本钱:经由过程增加GPU 应用量,明显下降推理本钱,合适中小企业或硬件资本无限的情况。现在该名目已支撑在GITHUB高低载,想要休会的同窗能够经由过程下365国际速发平台官网方地点自行搭载哦~https://github.com/deepseek-ai/FlashMLA,参数如下图所示;固然,手握花费级显卡的小搭档也不要悲观~公道应用PC硬件,当地安排一套DeepSeek-R1(INT-4)模子用来办公、进修也是不错的抉择!固然,最好是应用影驰最新推出的GeForceRTX 50系列显卡来停止当地安排!影驰GeForceRTX 50系列显卡采取NVIDIA全新Blackwell架构,搭载第二代Transformer引擎,支撑4位浮点(FP4) AI,从而减速年夜言语模子(LLM) 跟专家混杂模子(MoE)的推理跟练习!抉择它们作为你的出产力显卡,能够说是再适合不外!欢送列位小搭档们前去影驰官方商城选购哦~