电话:020-66888888

Shang Tang坐在Big Model的核心卡桌子上
作者:365bet亚洲体育 发布时间:2025-05-12 10:48
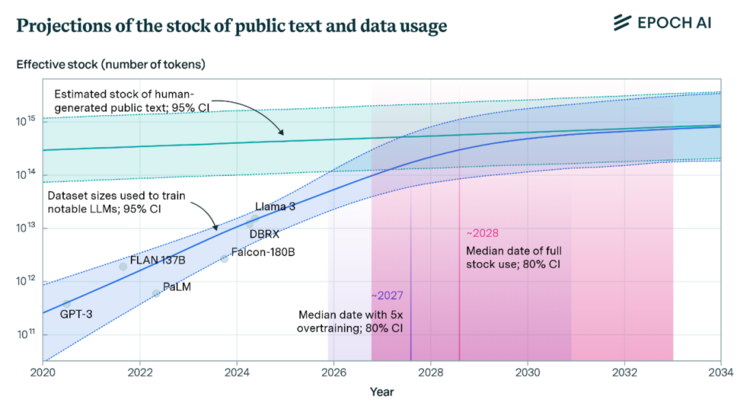 在过去的两年中,与大型模型的讨论观点很少从人工智能公司(例如Senseime)开始,该公司已经建立了十年,并且在小时候和中年积累了资源和技术。这种现象的主要原因是两个技术周期之间的多样性:在2023年之前,人工感觉智力智能技术的道路主要是计算机视觉模型,与Chatgpt代表的新技术浪潮不同:它主要集中在自然语言处理和参数模型上。一个是一种愿景,另一种是语言。从外界,这两条曲目从未有过直接的关系。但是,DeepSeek R1的释放使所有“戏剧性”变成了:在Thechatgpt之后,几乎所有的努力都被V3和R1删除,经过两年的历史,到达GPT-4卷。当新的sota出现在语言取向的基本模型中时,每个人都面临TWo选项:将Deptseek作为目标,并继续转换最强的语言模型,或者找到不同的竞争点。更不用说Deptseek的目的是AGI,下一代基本模型可能不仅仅是语言的数量。根据权威研究机构调查时期AI(如下所示),从数据资源的角度来看,用于训练大语言模型的文本数据正在迅速接近危机点;可以预测,到2028年,大型模型的培训数据范围将使用所有可用的文本Ininternet。同时,最近,语言模型逐渐反映了随着参数的大小的增加而降低边际性能益处的过程。因此,与大型语言模型的竞争相比,越来越多的顶级团队正在研究下一个AGI阶段:大型多式联运模型。遵循GPT-4O,OpenAI,Google和Meta等巨型技术Iz Ized许多强大的主要多模型模型,例如GPT-4.5,Gemini 2.0/2.5 Pro和Llama。经过两年的投资和努力,它不仅缩小了文本差距,而且在最新的大型多模式模型中积累了力量。根据4月10日的Senseime洗衣店,新一代的6000亿个模式“ RIRI New Sense Nova V6”模式可能与GPT-4.5和Gemini 2.0 Pro对齐,而Gemini 2.0 Pro在多模式的综合功能方面,甚至略有超越。不仅如此,Sang Tang还引入了一个长长的思维链,以深刻的思想领导了多模式的整合。实际上,自2024年中期以来,Senseime探索了民间融合多式联模型,并在R1发行和受欢迎程度之前出现在超级Clue和Opencomas中。 Senseime设备是领先的一半,而本机的多模式大型型号积累并赚了很多钱。在大型模型的浪潮中,全面的感觉竞争可能会被低估。 01。它是后面还是领先?一个令人难以置信的事实是:在更改大型模型技术的两年后,在前十年建立的算法的人工算法公司中,Senseime是少数可以快速转向视觉算法转向主要技术技术循环的AI公司之一,以及Algorithm的算法。它拥有两个主要通行证 - 大型设备和阳光日。当大型模型在2023年闻名时,Senseime用大型设备获得了大型型号的门票,并在该行业中创建了一个千卡瓦群,该集群提供了不到一个月的出色模型培训。它不仅在计算强度的巨大回报上进行了有机赛的投资,并开始赚取收入,而且还赢得了Seensime的时间,以跟上基本的模型研究。如果大型的感官设备至少领导该行业3年,而Ringtime的正式发布比该行业晚了一年,它将协调计算和算法的力量,并将其协调。实际上,在过去十年中积累了实用的商业化经验,实际上,在该行业早些时候1 - 2年前,大型模型的全面力量。在Sinsenova V6之后,融合多模式的本机模型独立发布,差距至少扩大了半年。你为什么这么说?由于当前本地多模式大型模型的技术难度仍然很高,因此Senseime的RIRI-NEW V6能够匹配国际领先的大型GPT-4.5和Gemin Modelsi 2.0 Pro。尽管在过去两年中,在国内外发布了大量的多模型模型结果,但很少有多模型模型能够真正包含至少两个模态数据,例如文本,语音,图像和视频在输入和输出端,以及完整的活动,例如理解,理解,理解,对决策制定和生成。它需要从基础体系结构,高质量数据P的一般更改上层算法的尿素化。例如,尽管变压器在文本的多年生列表中很棒,但长期以来一直有人说,它需要在多模式甚至空间智能上进行改进,而且没有人在暴力之前就设定奇迹。最新的案例可以定义为元元发布的骆驼。 4。尽管投资很大,但非常小。当前,多模型模型的广泛研究方法可以分为两条途径:一种是从语言模型开始,并根据语言模型将其他模式(例如语音和图像)叠加;其他人将从视觉和叠加语言,语音,愿景和其他模式(例如图像和视频)等语言,言语,愿景和视频。此外,多模式研究最终还具有AIGC追逐和AGI Chase之间的差异,这是指多模型模型研究之间的广泛差异。当前,多模式模型主要基于E大小为10亿个参数。其背后的主要原因是两个点:首先,多模型模型消耗的计算强度大于纯语言模型。其次,当多模式模型的标准尺度升至道路水平千分之二美元时,将进行不同模式之间的数据组合。互相抓住而不是成长和跌倒的困难也变得更大。一个研究团队曾经在Leifeng.com上描述了一个研究问题:当他们试图以超过5000亿个模式的100亿文本模型扩展时,添加的图像,视频和语言数据显示出一种降低文本数据文本性能的现象。可以从中可以发现,很难获得具有多模式数据量表的高水平的多模式大型模型,该模型扩展到数百亿美元,许多模式可以“互相支持”。根据Senseime和C执行总监Lin Dahua的说法人工智能基础架构和伪造的hif科学家,Senseime开始相信自2024年5月的GPT-4O自发布以来,多模式模型一直是未来,因此它迅速开始研究。最初,Senseime还采用了传统的“核心模式 +第二模式”途径,但是在另一种模式下一种模式削弱而没有达到1 + 1 2的影响,这是一个问题。此后,它花费了很多时间来处理两种模式之间的桥梁技术。去年12月,“双王冠之王”受过训练,以证明其本地融合路线。基于12月的融合模型,Sinsenova V6继续实施新一代的融合融合多模型Sinsenoova V6,参数量表为6000亿。根据官方审查数据,V6不仅是GPT-4.5和Gemini 2.0 Pro基准在全面的多模式活动中,Ngunit还比较了DeepSeek V3(请参见下表),而推理功能和相比的推理功能进行了比较。到GPT-O1(请参见下表):注意:Google Gemini 2.5 Pro仅少于一个月,并且在不同指标的不同指标的指标上没有公开评论,用于不同指标的不同指标。主要技术可以分为两个部分:一个是多模式的主要桥梁。在模型的预训练阶段,诸如文本,语音,视频和图像之类的数据被合并为训练,以使不同的模式相互适合并与相同的上下文窗口对齐;其余的是对DeepSeek和前半步骤的主要思想的参考,该思想被专门显示为对Israchain链和输出RL多模式的长时间思考的融合(增强研究)。 DeepSeek主要基于文本,而Senseime着重于从头到尾开发大型多模型。因此,在深入思考和研究强化的技术中,它也需要多模式作为父母,并导致探索长-IMA多模型模型的链结构。据了解,特工产生的思想链的总储量超过1000万。 RIRI-NEW V6可以产生高质量的精神链,最多可达64K,这意味着感觉到的多模式模型可以在回答用户问题以生成全局内存之前具有超过60,000个深入的词。 Sensetime的独特功能是,在开发PAG链的过程中,每个步骤都将使用以前的图形多模式信息和文本,以及全面的推理情况来采取下一步思考和推理的步骤。换句话说,V6中推理的每个步骤都具有与逻辑思维的混合性的形象性心态 - 与纯语言思维链相比,这也是一个巨大的差异。在过去大型模型的纯语言,但在多模型中学习也有更高的卓越性。根据Lin Dahua的供认,V6并未完全消除大型模型的幻觉问题,而是通过审查输入数据的质量和输出中的集成RL来减轻幻觉问题。与DeepSeek R1相比,V6奖励信号更丰富,包括结果,RLHF奖励,并判断语言描述是否通过视觉理解与图像和视频一致,等等;同时,在模型思维过程中,基于事实而不是奖励的加强研究是在阶段进行的。在大型多模型模型的实践中,由于大型设备和大型模型之间的密切协调,Senseime V6的训练和识别得到了高度优化。根据Senseime技术的联合创始人兼大型设备业务集团总裁Yang Fan的说法E卓越的感官实践训练Deptseek模型本身要比原始Pabrika发布的指标更好。 Senseime设备每张卡最多可达1,600多个令牌,并且向官方Deptseek官员披露的数据为1,500多个令牌。除了大型设备外,Senspartots还拥有第一个在其自己的发动机训练Sensepartot上进行千card训练的系统。此外,自2018年以来,Senseime以及提供至少20%的国内芯片的数量已经使用了国内芯片进行模型培训,并且V6培训的一部分也在国内芯片上进行。在推理方面,感官设备采用了PD隔离,通信复制,FP8增强和操作员合作,以提高效率,并且在线理解服务的性能超过了25%的行业的平均水平;就离线理解而言,KCompared可以打开资源解决方案,在预填充阶段,Senseime设备的速度快5倍,3.5 TIME在解码阶段更快。 DeepSeek在大型语言模型轨道上的复出表明,长时间的AGI运行需要计算计算强度和算法功能。与纯语言模型相比,大型的多模式模型需要在训练和推理方面提高计算能力,并且在长期差距上积累了轻度发展。技术可能不会发展无敌的障碍,但它可以赢得有益于竞争的时间的差异。 Senseime V6比本地多模式大型模型和深层的多式联运思维和推理领先一半,毫无疑问,在大型模型行业中提供了NG信息:Leifeng.com(公共帐户:Leifeng.com)Senseime,它已经前往两个技术周期,已经坐在主模型表位置。 02。广泛的竞争,当大型模型市场中的感官位置被重新评估时,这个小的AI巨人(与初创企业相比,它都不比蝙蝠大,也不小,它显示出独特的优势。从技术上讲,AGI与数据,算法和计算能力一致。数据层,新的感官多模式模型表明,其集成是各种模态数据的容量,例如文本,图像,3D,视频等;计算能力的算法和层次,Senseime的十年积累至少是具有云计算和基本模型的互联网制造商,但是尽管两者具有很多相似之处,但仍然存在重要的差异。这种差异反映在“终止思维”的主要差异中:互联网制造商研究基本模型的最终目的通常会创建一个随着流量收集而创建的“超级应用”。自成立的第一天以来,Senseime已成为一家“人工智能”公司,其最终目标参与了人工智能时期的建设。因此,在大型模型的商业实施中,Senseime在B和C之间没有癫痫发作。如果是算法M或计算的力量,Senseime愿意成为行业中的“渡轮”。将算法差距捆绑在一起时,技术明星终于返回了尘土飞扬的土地。在大型模型的商业化中,Senseime在过去的DECADA中已经积累了各个行业的经验,并且自然的维度降低了命中率 - 当初创企业仍在学习在购物中心行走时,Senseime已经踏入坑里并越过山丘。与DeepSeek不同,大型模型中对感官的思想不仅是基本模型的研究成功,而且是模型的商业实施。过去,Senseime本身已经达到了许多业务,包括手机,汽车和营销以及基于业务的精制要求,也指导了模型功能的优化。以Ririxin V6为例,Senseime追求本地多模式,并强调MO的三个基本技能DEL:推理能力,情感共鸣和能力实时接触以及对我的长期记忆/全球能力。根据Senseime V6连接到的场景,在大型着陆模型的情况下,基本的联系方法不仅是文本,而且实时视频呼叫的流量很大。与文本类似,视频触点对较长的视频输出窗口和模型的长期内存能力有很高的要求。 V6最多可以支持10分钟的完整视频输入,形成语音,文本和视频的统一上下文表达,然后进行深入的理解,分析和推理。在与流媒体的接触方面,自GPT-4O发布以来,Senseime坚持创建多模式联系门户。从概念的意义上讲,通过终端与人进行多模式相互作用的大型模型必须是Magaan模型,而不是600B基本模型。此外,与人的实时接触还提出了很高的要求模型和拟人化表达能力的情绪同理心。根据统计数据,Senseime是中国在拟人对话引擎外的第二大供应商。基于新的Riji新本机多模型模型,Senseime建议“一个基础和两个机翼”实施计划:所谓的“两个机翼”是指在具体的智能,硬件,眼镜等方向上应用的智能联系。例如,接触多模式综合能力和多模式深思熟虑和推理的多模式拟人化的方法与高情绪智力相结合是响应日常频率需求,例如数学问题解决,文化阅读,文化和旅游业的解释,照片图书解释,相册的解释等,都比以前的多种模态模型实现了更好的性能。同样,在具体智能领域,Senseime与机器人制造商合作例如,探索将V6整合到终端的可能性。根据RIRI新V6的多模式融合的能力,机器人可以同时掌握许多感官,例如“大脑”,“耳朵”,“眼”和“口”,并通过集成信息并进行深入思考来理解环境。在小浣熊系列中,对V6和推理能力的多模式深思熟虑。 Little Raccoon不仅支持结构化数据,例如Excel和数据库,而且支持非结构性数据分析,例如Word,PDF,TXT和Photos,并支持与数据资源集成的分析。审查的准确性超过了TableBench上的GPT-4O和1000多个数据审核方案。根据Senseime 2024年的财务报告,Senseime业务收入达到24亿元人民币,价值约为总收入的63.7%,同比增长100%以上。当前的大型模型尚未实施情况,但是产品有效性的生命和死亡线。作为多年来已经上升并陷入商业世界的“ OG”,Senseime收紧了生存的第一个原则,如果是大型Aparato和大型模型的协调,或者商业方法对B的关注比C更关注B。以C.以机器人为例。通过促进大型多模型模型,终端智能只能使用一个模型实现许多功能,而不是多模型模型和语言模型的要求,这更有效。 Senseime具有自己的C端应用程序,但是从当前大型商业化的角度来看,其重点主要是B端服务。从建立人工智能时期的“终点思维”的角度来看,促进更多的行业和更多的“ AI-native”需求比增加对Superapp追求的投资更重要。 Leifeng.com目前,Sensei我支持许多名人c-end应用程序,包括WPS,文学和思想流。一方面,它可以在驱动数据飞轮时紧密联系业务技术。计算,算法,用户和业务的功能是一个完整的模型系统,任何链接的快速旋转将导致其他链接的跳跃。在大型模型的浪潮中,Senseime的启动飞轮积累了大型设备和广告。在RIRI新大型模型系列发布后,多模式大型感觉模型的强度大大改善,尤其是因为V6的主要成功也使飞轮算法反映了巨大的潜力。前一步是一个疯子,而一步是一个天才。从大型安装到RIRI New V6的V6,Sensetime将准确预测每个技术趋势,并迅速实现里程碑成就。如果算法可以主导下一个senseime模型的下一个NA巨型飞轮,那么肯定是Orth在等待和看。
在过去的两年中,与大型模型的讨论观点很少从人工智能公司(例如Senseime)开始,该公司已经建立了十年,并且在小时候和中年积累了资源和技术。这种现象的主要原因是两个技术周期之间的多样性:在2023年之前,人工感觉智力智能技术的道路主要是计算机视觉模型,与Chatgpt代表的新技术浪潮不同:它主要集中在自然语言处理和参数模型上。一个是一种愿景,另一种是语言。从外界,这两条曲目从未有过直接的关系。但是,DeepSeek R1的释放使所有“戏剧性”变成了:在Thechatgpt之后,几乎所有的努力都被V3和R1删除,经过两年的历史,到达GPT-4卷。当新的sota出现在语言取向的基本模型中时,每个人都面临TWo选项:将Deptseek作为目标,并继续转换最强的语言模型,或者找到不同的竞争点。更不用说Deptseek的目的是AGI,下一代基本模型可能不仅仅是语言的数量。根据权威研究机构调查时期AI(如下所示),从数据资源的角度来看,用于训练大语言模型的文本数据正在迅速接近危机点;可以预测,到2028年,大型模型的培训数据范围将使用所有可用的文本Ininternet。同时,最近,语言模型逐渐反映了随着参数的大小的增加而降低边际性能益处的过程。因此,与大型语言模型的竞争相比,越来越多的顶级团队正在研究下一个AGI阶段:大型多式联运模型。遵循GPT-4O,OpenAI,Google和Meta等巨型技术Iz Ized许多强大的主要多模型模型,例如GPT-4.5,Gemini 2.0/2.5 Pro和Llama。经过两年的投资和努力,它不仅缩小了文本差距,而且在最新的大型多模式模型中积累了力量。根据4月10日的Senseime洗衣店,新一代的6000亿个模式“ RIRI New Sense Nova V6”模式可能与GPT-4.5和Gemini 2.0 Pro对齐,而Gemini 2.0 Pro在多模式的综合功能方面,甚至略有超越。不仅如此,Sang Tang还引入了一个长长的思维链,以深刻的思想领导了多模式的整合。实际上,自2024年中期以来,Senseime探索了民间融合多式联模型,并在R1发行和受欢迎程度之前出现在超级Clue和Opencomas中。 Senseime设备是领先的一半,而本机的多模式大型型号积累并赚了很多钱。在大型模型的浪潮中,全面的感觉竞争可能会被低估。 01。它是后面还是领先?一个令人难以置信的事实是:在更改大型模型技术的两年后,在前十年建立的算法的人工算法公司中,Senseime是少数可以快速转向视觉算法转向主要技术技术循环的AI公司之一,以及Algorithm的算法。它拥有两个主要通行证 - 大型设备和阳光日。当大型模型在2023年闻名时,Senseime用大型设备获得了大型型号的门票,并在该行业中创建了一个千卡瓦群,该集群提供了不到一个月的出色模型培训。它不仅在计算强度的巨大回报上进行了有机赛的投资,并开始赚取收入,而且还赢得了Seensime的时间,以跟上基本的模型研究。如果大型的感官设备至少领导该行业3年,而Ringtime的正式发布比该行业晚了一年,它将协调计算和算法的力量,并将其协调。实际上,在过去十年中积累了实用的商业化经验,实际上,在该行业早些时候1 - 2年前,大型模型的全面力量。在Sinsenova V6之后,融合多模式的本机模型独立发布,差距至少扩大了半年。你为什么这么说?由于当前本地多模式大型模型的技术难度仍然很高,因此Senseime的RIRI-NEW V6能够匹配国际领先的大型GPT-4.5和Gemin Modelsi 2.0 Pro。尽管在过去两年中,在国内外发布了大量的多模型模型结果,但很少有多模型模型能够真正包含至少两个模态数据,例如文本,语音,图像和视频在输入和输出端,以及完整的活动,例如理解,理解,理解,对决策制定和生成。它需要从基础体系结构,高质量数据P的一般更改上层算法的尿素化。例如,尽管变压器在文本的多年生列表中很棒,但长期以来一直有人说,它需要在多模式甚至空间智能上进行改进,而且没有人在暴力之前就设定奇迹。最新的案例可以定义为元元发布的骆驼。 4。尽管投资很大,但非常小。当前,多模型模型的广泛研究方法可以分为两条途径:一种是从语言模型开始,并根据语言模型将其他模式(例如语音和图像)叠加;其他人将从视觉和叠加语言,语音,愿景和其他模式(例如图像和视频)等语言,言语,愿景和视频。此外,多模式研究最终还具有AIGC追逐和AGI Chase之间的差异,这是指多模型模型研究之间的广泛差异。当前,多模式模型主要基于E大小为10亿个参数。其背后的主要原因是两个点:首先,多模型模型消耗的计算强度大于纯语言模型。其次,当多模式模型的标准尺度升至道路水平千分之二美元时,将进行不同模式之间的数据组合。互相抓住而不是成长和跌倒的困难也变得更大。一个研究团队曾经在Leifeng.com上描述了一个研究问题:当他们试图以超过5000亿个模式的100亿文本模型扩展时,添加的图像,视频和语言数据显示出一种降低文本数据文本性能的现象。可以从中可以发现,很难获得具有多模式数据量表的高水平的多模式大型模型,该模型扩展到数百亿美元,许多模式可以“互相支持”。根据Senseime和C执行总监Lin Dahua的说法人工智能基础架构和伪造的hif科学家,Senseime开始相信自2024年5月的GPT-4O自发布以来,多模式模型一直是未来,因此它迅速开始研究。最初,Senseime还采用了传统的“核心模式 +第二模式”途径,但是在另一种模式下一种模式削弱而没有达到1 + 1 2的影响,这是一个问题。此后,它花费了很多时间来处理两种模式之间的桥梁技术。去年12月,“双王冠之王”受过训练,以证明其本地融合路线。基于12月的融合模型,Sinsenova V6继续实施新一代的融合融合多模型Sinsenoova V6,参数量表为6000亿。根据官方审查数据,V6不仅是GPT-4.5和Gemini 2.0 Pro基准在全面的多模式活动中,Ngunit还比较了DeepSeek V3(请参见下表),而推理功能和相比的推理功能进行了比较。到GPT-O1(请参见下表):注意:Google Gemini 2.5 Pro仅少于一个月,并且在不同指标的不同指标的指标上没有公开评论,用于不同指标的不同指标。主要技术可以分为两个部分:一个是多模式的主要桥梁。在模型的预训练阶段,诸如文本,语音,视频和图像之类的数据被合并为训练,以使不同的模式相互适合并与相同的上下文窗口对齐;其余的是对DeepSeek和前半步骤的主要思想的参考,该思想被专门显示为对Israchain链和输出RL多模式的长时间思考的融合(增强研究)。 DeepSeek主要基于文本,而Senseime着重于从头到尾开发大型多模型。因此,在深入思考和研究强化的技术中,它也需要多模式作为父母,并导致探索长-IMA多模型模型的链结构。据了解,特工产生的思想链的总储量超过1000万。 RIRI-NEW V6可以产生高质量的精神链,最多可达64K,这意味着感觉到的多模式模型可以在回答用户问题以生成全局内存之前具有超过60,000个深入的词。 Sensetime的独特功能是,在开发PAG链的过程中,每个步骤都将使用以前的图形多模式信息和文本,以及全面的推理情况来采取下一步思考和推理的步骤。换句话说,V6中推理的每个步骤都具有与逻辑思维的混合性的形象性心态 - 与纯语言思维链相比,这也是一个巨大的差异。在过去大型模型的纯语言,但在多模型中学习也有更高的卓越性。根据Lin Dahua的供认,V6并未完全消除大型模型的幻觉问题,而是通过审查输入数据的质量和输出中的集成RL来减轻幻觉问题。与DeepSeek R1相比,V6奖励信号更丰富,包括结果,RLHF奖励,并判断语言描述是否通过视觉理解与图像和视频一致,等等;同时,在模型思维过程中,基于事实而不是奖励的加强研究是在阶段进行的。在大型多模型模型的实践中,由于大型设备和大型模型之间的密切协调,Senseime V6的训练和识别得到了高度优化。根据Senseime技术的联合创始人兼大型设备业务集团总裁Yang Fan的说法E卓越的感官实践训练Deptseek模型本身要比原始Pabrika发布的指标更好。 Senseime设备每张卡最多可达1,600多个令牌,并且向官方Deptseek官员披露的数据为1,500多个令牌。除了大型设备外,Senspartots还拥有第一个在其自己的发动机训练Sensepartot上进行千card训练的系统。此外,自2018年以来,Senseime以及提供至少20%的国内芯片的数量已经使用了国内芯片进行模型培训,并且V6培训的一部分也在国内芯片上进行。在推理方面,感官设备采用了PD隔离,通信复制,FP8增强和操作员合作,以提高效率,并且在线理解服务的性能超过了25%的行业的平均水平;就离线理解而言,KCompared可以打开资源解决方案,在预填充阶段,Senseime设备的速度快5倍,3.5 TIME在解码阶段更快。 DeepSeek在大型语言模型轨道上的复出表明,长时间的AGI运行需要计算计算强度和算法功能。与纯语言模型相比,大型的多模式模型需要在训练和推理方面提高计算能力,并且在长期差距上积累了轻度发展。技术可能不会发展无敌的障碍,但它可以赢得有益于竞争的时间的差异。 Senseime V6比本地多模式大型模型和深层的多式联运思维和推理领先一半,毫无疑问,在大型模型行业中提供了NG信息:Leifeng.com(公共帐户:Leifeng.com)Senseime,它已经前往两个技术周期,已经坐在主模型表位置。 02。广泛的竞争,当大型模型市场中的感官位置被重新评估时,这个小的AI巨人(与初创企业相比,它都不比蝙蝠大,也不小,它显示出独特的优势。从技术上讲,AGI与数据,算法和计算能力一致。数据层,新的感官多模式模型表明,其集成是各种模态数据的容量,例如文本,图像,3D,视频等;计算能力的算法和层次,Senseime的十年积累至少是具有云计算和基本模型的互联网制造商,但是尽管两者具有很多相似之处,但仍然存在重要的差异。这种差异反映在“终止思维”的主要差异中:互联网制造商研究基本模型的最终目的通常会创建一个随着流量收集而创建的“超级应用”。自成立的第一天以来,Senseime已成为一家“人工智能”公司,其最终目标参与了人工智能时期的建设。因此,在大型模型的商业实施中,Senseime在B和C之间没有癫痫发作。如果是算法M或计算的力量,Senseime愿意成为行业中的“渡轮”。将算法差距捆绑在一起时,技术明星终于返回了尘土飞扬的土地。在大型模型的商业化中,Senseime在过去的DECADA中已经积累了各个行业的经验,并且自然的维度降低了命中率 - 当初创企业仍在学习在购物中心行走时,Senseime已经踏入坑里并越过山丘。与DeepSeek不同,大型模型中对感官的思想不仅是基本模型的研究成功,而且是模型的商业实施。过去,Senseime本身已经达到了许多业务,包括手机,汽车和营销以及基于业务的精制要求,也指导了模型功能的优化。以Ririxin V6为例,Senseime追求本地多模式,并强调MO的三个基本技能DEL:推理能力,情感共鸣和能力实时接触以及对我的长期记忆/全球能力。根据Senseime V6连接到的场景,在大型着陆模型的情况下,基本的联系方法不仅是文本,而且实时视频呼叫的流量很大。与文本类似,视频触点对较长的视频输出窗口和模型的长期内存能力有很高的要求。 V6最多可以支持10分钟的完整视频输入,形成语音,文本和视频的统一上下文表达,然后进行深入的理解,分析和推理。在与流媒体的接触方面,自GPT-4O发布以来,Senseime坚持创建多模式联系门户。从概念的意义上讲,通过终端与人进行多模式相互作用的大型模型必须是Magaan模型,而不是600B基本模型。此外,与人的实时接触还提出了很高的要求模型和拟人化表达能力的情绪同理心。根据统计数据,Senseime是中国在拟人对话引擎外的第二大供应商。基于新的Riji新本机多模型模型,Senseime建议“一个基础和两个机翼”实施计划:所谓的“两个机翼”是指在具体的智能,硬件,眼镜等方向上应用的智能联系。例如,接触多模式综合能力和多模式深思熟虑和推理的多模式拟人化的方法与高情绪智力相结合是响应日常频率需求,例如数学问题解决,文化阅读,文化和旅游业的解释,照片图书解释,相册的解释等,都比以前的多种模态模型实现了更好的性能。同样,在具体智能领域,Senseime与机器人制造商合作例如,探索将V6整合到终端的可能性。根据RIRI新V6的多模式融合的能力,机器人可以同时掌握许多感官,例如“大脑”,“耳朵”,“眼”和“口”,并通过集成信息并进行深入思考来理解环境。在小浣熊系列中,对V6和推理能力的多模式深思熟虑。 Little Raccoon不仅支持结构化数据,例如Excel和数据库,而且支持非结构性数据分析,例如Word,PDF,TXT和Photos,并支持与数据资源集成的分析。审查的准确性超过了TableBench上的GPT-4O和1000多个数据审核方案。根据Senseime 2024年的财务报告,Senseime业务收入达到24亿元人民币,价值约为总收入的63.7%,同比增长100%以上。当前的大型模型尚未实施情况,但是产品有效性的生命和死亡线。作为多年来已经上升并陷入商业世界的“ OG”,Senseime收紧了生存的第一个原则,如果是大型Aparato和大型模型的协调,或者商业方法对B的关注比C更关注B。以C.以机器人为例。通过促进大型多模型模型,终端智能只能使用一个模型实现许多功能,而不是多模型模型和语言模型的要求,这更有效。 Senseime具有自己的C端应用程序,但是从当前大型商业化的角度来看,其重点主要是B端服务。从建立人工智能时期的“终点思维”的角度来看,促进更多的行业和更多的“ AI-native”需求比增加对Superapp追求的投资更重要。 Leifeng.com目前,Sensei我支持许多名人c-end应用程序,包括WPS,文学和思想流。一方面,它可以在驱动数据飞轮时紧密联系业务技术。计算,算法,用户和业务的功能是一个完整的模型系统,任何链接的快速旋转将导致其他链接的跳跃。在大型模型的浪潮中,Senseime的启动飞轮积累了大型设备和广告。在RIRI新大型模型系列发布后,多模式大型感觉模型的强度大大改善,尤其是因为V6的主要成功也使飞轮算法反映了巨大的潜力。前一步是一个疯子,而一步是一个天才。从大型安装到RIRI New V6的V6,Sensetime将准确预测每个技术趋势,并迅速实现里程碑成就。如果算法可以主导下一个senseime模型的下一个NA巨型飞轮,那么肯定是Orth在等待和看。